実験でプログラミングしたMicroPythonの簡単な説明です。
記法について
変数名やクラス名等の記法については、次のとおりです。
| 種 類 | 記 法 | 例 |
| 変数名 | スネークケース | snake_case |
| 定数 | スネークケース(大文字) | SNAKE_CASE |
| 関数名 | スネークケース | snake_case |
| クラス名 | パスカルケース | PascalCase |
| モジュール名 | スネークケース | snake_case |
| パッケージ名 | 英小文字のみ (アンダースコアなし) | lowercase |
変数
数値等のデータを一時的にメモリ上に保管する場所を「変数」と言い、保管場所の名前を「変数名」と言います。
MicroPythonは宣言した変数名に値を代入することで、メモリ上に保管場所が自動的に確保されます。
JavaやC#のように、変数と変数に保管する数値、文字など データの型を宣言する必要はありません。
プログラムコードで変数に最初に値を代入することを「初期化」と言います。
代入は次のように、変数名を左辺に格納する値を右辺に設定し、左辺と右辺を「等号(=)」でつなぎます。
<例>
- val = 123
変数の内容を確認するためには、関数や式の中で変数名を指定します。変数名を指定して変数の値を取り出すことを「参照」と言います。
<例>
- print(val) → 123
変数名は「識別子」と言われる一定の規則にしたがって設定します。
- 半角英数字、アンダースコアを使い、それ以外の文字は使えません。
- 頭の文字に数字は使えません。
- 大文字と小文字区別します。
- 予約語と言わるあらかじめ決められた文字(for、ifなど)は使えません。
- 文字数や命名に制限がありませんが、単語を省略するなどわかり易い文字列にしたり、記法を統一します。
データ型の基本
データ型はデータの種類のことで、次のよく使うデータ型がMicroPythonに最初から組み込まれています。
- 文字列型
- 整数型
- 浮動小数点型
- 論理値型
- 特殊な型「None」
- リスト
変数の項でも書きましたが、MicroPythonは変数と変数に保管する数値、文字など データの型を宣言する必要はありません。
変数に保存できる値や、プログラムコードの中に、特定のデータ型の値を直接記述するものを「リテラル」と言います。
- 文字列型 : 文字列リテラル
- 整数型 : 整数リテラル
- 浮動小数点型 : 浮動小数リテラル
- 論理値型 : 論理値リテラル
変数の内容に応じて、自動的に型が変わりますので、同じ変数(変数名)に異なるデータ型の値を代入できます。
<例>
- val = 123 整数型を代入
- val = “ABC” 文字列型を代入
文字列型
文字列リテラルは、一重引用符「’’」または二重引用符「””」で文字列を囲って表記されます。
▶️ 文字列リテラルの表記
一重引用符「’’」、二重引用符「””」にどちらを使っても構いません。
<例>
- ‘Hello’
- “Hello”
文字の中に一重引用符「’’」、二重引用符「””」がある場合は、一重引用符「’’」、「二重引用符「””」で囲うことで使いわけができます。
<例>
- “‘Hello’” → ‘Hello’と表示されましす。
(一重引用符を 二重引用符で囲んだ場合) - ‘“Hello”’ → “Hello”と表示されましす。
(二重引用符を 一重引用符で囲んだ場)
▶️特殊文字の表記
文字列の中に「改行」や「タブ」などの特殊な文字を入れたい場合は、エスケープシーケンスを使います。
エスケープシーケンスは「バックスラッシュ + 特殊文字」(※Windowsではバックスラッシュは「¥」となります。)
<例>
- “Hello \n World” → 改行されて表示されます。
Hello
World
よく使うエスケープシーケンス
- \n 改行
- \\ バックスラッシュ
- \t タブ
- \’ 一重引用符
- \” 二重引用符
▶️文字列の演算
- 「+」記号を使って文字列を結合します。
“abc” + “def” → ‘abcdef’ - 「*」を使って文字列を繰返します。
“yz” * 3 → ‘yzyzyz’ - 「len()」関数を使って文字列の長さを求めます。
len(“abcde”) → 5
▶️ 文字(文字列)の取り出し
文字列の中から、指定した「文字」や「文字列」を取り出すことができます。
- 文字の取り出しは、角かっこ「[]」で文字の位置を1つ指定します。
・s = “ABCDFG”
・s[0] → ‘A’
・s[4] → ‘F’
先頭の文字の位置を「0」番目の文字として考えます。 - 文字列の取り出しは、取り出す文字列の開始位置と終了位置を、角かっことコロン「[:]」で指定します。
・s = “ABCDEFGHIJ”
・s[0:4] → ‘ABCD’ 0文字目から3文字目までの文字列
・s[1:5] → ‘BCDE’ 1文字目から4文字目までの文字列
・s[3:] → ‘DEFG’ 3文字目以降の文字列
・s[:-2] → ‘ABSDEFGH’ 後から3文字目以前の文字列
・s[-5:] → ‘FGHIJ’ 後から4文字目以降の文字列
マイナスの場合は逆順となり、末尾の文字の位置を「0」番目の文字として考えます。
このような表記方法を「スライス」と言います。
整数型
整数は1、15、100のような小数点のない数値で、整数リテラルは、整数を直接表記したもので、使用するマイコンのメモリ容量の許す限りの大きな値を扱うことができます。
整数リテラルは文字リテラルのように、一重引用符「’’」または二重引用符「””」で数値を囲ってはいけません。
▶️整数リテラルの表現方法
整数リテラルには4種類の表現方法があります。
- 10進数 : 日常的に使う正数(18)、負数(-109)、ゼロ(0)を表現します。
・10 : 10進数の10 - 16進数 : 0~9、a~fを使って、10進数の0~15を表現します。
数値の先頭に「0x(ゼロとエックス)」をつけます。
・0x10 : 16進数の10 → 10進数の16
・0xf : 16進数のf → 10進数の15 - 8進数 : 0~7使って、10進数の0~7を表現します。
値の先頭に「0o(ゼロとオー)」をつけます。
・0o10 : 8進数の10 → 10進数の8 - 2進数 : 0、1使って、10進数の0~1を表現します。
値の先頭に「0b(ゼロとビー)」をつけます。
・0b10 : 2進数の10 → 10進数の2
数字列の任意の位置に 「アンダースコア( _ )」を挿入できます。
<例>
- 2_000_000 → 2000000 (3桁区切り)
▶️整数の演算
整数の演算は次のとおりです。
| 演算子 | 演算子 | 例 | 結果 |
| + | 加算 | 5 + 4 | 9 |
| - | 減算 | 7 - 4 | 3 |
| * | 乗算 | 3 * 2 | 6 |
| ** | べき乗 | 2 ** 3 | 8 |
| / | 除算 | 5 / 3 | 1.66666 |
| // | 除算(切捨て) | 7 / 3 | 2 |
| % | 剰余(余った残り) | 7 % 3 | 1 |
| divmod | 商と余り | divmod(7, 3) | (2, 1) |
浮動小数点型
浮動小数点型は3.4や0.02のように、小数点が付いた数値だけでなく、指数表現(<仮数部>e<符号><指数部>)される値です。
浮動小数点型の精度は、C言語のFloat型に精度「1.17549e-38 〜 3.40282e+38(±10-38 〜 1038) 」と同様と思われます。
浮動小数点リテラルは、小数部または整数部がゼロ(0)の場合は、ゼロ(0)を省略できます。
<例>
- 2. → 2.0
- .2 → 0.2
- . → 0.0 エラー 0.0はゼロ(0)を省略できません。
指数「α X10N 」は指数数表現(<仮数部>e<符号><指数部>)で表わすことができます。
<例>
- 1.23e3 → 1230.0
- 1.23e-2 → 0.0123
▶️浮動小数点の演算
浮動小数点は「divmod」を除き、整数の演算と同様な演算ができます。
論理値型
論理値型は「True(真)」と「False(偽)」のいずれかの状態を持ち、「比較式」や「論理式」の計算結果を表わすために使われます。
▶️ 比較演算子
比較演算子は、演算子の右辺、左辺の値の一致、不一致、大小関係、及び演算子の右辺、左辺のオブジェクトの参照を比較します。
比較演算子は次のとおりです。
| 演算子 | Trueになる条件 | 例 | 結果 |
| == | 右辺が左辺に等しい | 5 == 10 | False |
| != | 右辺が左辺に等しくない | 5 != 10 | True |
| > | 右辺より左辺が大きい | 5 >10 | False |
| >= | 右辺より左辺が大きいか等しい | 5 >=10 | False |
| < | 右辺より左辺が小さい | 5 <10 | True |
| <= | 右辺より左辺が小さいか等しい | 5 <=10 | True |
| in | 右辺が左辺に存在する | 5 in [0, 5, 10] | True |
| not in | 右辺が左辺に存在しない | 5 not in [0, 5, 10] | False |
| is | 右辺と左辺が同一である | 5 is10 | False |
| is not | 右辺と左辺が同一でない | 5 is not10 | True |
「==」演算子と「is」演算子は似ていますが、「==」演算子はオブジェクトの値が等しいかを判定し(同値性)、「is」演算子はオブジェクトが同じかを判定(同一性)します。
<例>
- val1 = 123
- val2 = 123
- val3 = val1
- val1 == val2 → True 別々のブジェクトが、同じ値を持っている
- val1 is val2 → False :同じ値を持っていても、別々のオブジェクト
- val1 is val3 → True : 同じ値を持っている別々の変数名でも、同じオブジェクト
▶️論理演算子
論理演算子は、複数の論理値(True、False)の「論理和」、「論理積」、「否定」の演算を行います。
論理演算子は次のとおりです。
| 演算子 | 内容 | 例 | 結果 |
| or | 論理和 | val == 5 or val <=10 | 変数valの値が5または10以下の時はTrue |
| and | 論理積 | 10 > 5 and 3==1 | False |
| not | 否定 | not (val == 7) | 変数valの値が7以外の時はTrue |
特殊な型「None」
Noneは「値が空」であることを表わす特別な型で、値は「None」だけです。
主に値が存在しないことを表わす目的で使われ、判定する場合は「==」演算子ではなく、「is」演算子を使います。
<例>
- val is None (val == Noneは使わない)
リスト
リストは、複数のデータをまとめて扱う仕組みである「コレクション(コンテナ)」の一つです。
リストには同一または異なるデータ型の値を、要素と呼ばれる入れ物に保存できます。
「配列」は要素が同じデータ型の集まりで、リストに要素をリストにした場合は「多次元配列」となります。
▶️リストの作成
リストに保存したい要素をカンマで区切って、角かっこで囲んで作成し、通常はリストを表わす任意の変数に代入します。
<例>
- data1 = [1, 2, 3, 4] : 一般的なリスト
- data2 = [1, ”abc”, 3.14, 3+5j] : 異なる型のリスト
- data3 = [[1, 2], [5, 6], [23, 59]] : リストに要素をリストした多次元配列
- data4 = [] : 空のリスト(要素が一つもない)
作成は要素を個別に直接設定する方法の他に、数列(0, 1, 2 ,3 ,4)のような一つずつ順番に取り出せる構造を持ったデータを変換して設定する方法もあります。
▶️要素の値を取得
リスト内の要素は、要素の場所を角かっこ([])で囲ったインデックス(添字)を使って取得します。
インデックス値は一文字目を「1」ではなく「0」として扱います。
負のインデックス値は最後の文字を「-1」として扱います。
<例:一般的なリストから取得>
- data1 = [1, 2, 3 ,4 ,5]
- data1[0] → 1
- data1[3] → 4
- data1[-3] → 3
<例:2次元配列から取得>
- data2 = [[A, B], [C, D]]
- data2[1, 0] → C
スライスは「リスト名[開始位置:終了位置:間隔]」に形式で表わされます。
開始位置の文字はインデックス値が表わされますが、終了位置の文字はインデックス値ではなく、開始位置の文字から「終了位置 ー 開始位置」番目の文字を表わします。
<例:範囲を指定(スライス)して取得>
- data3 = [1, 2, 3 ,4 ,5, 6, 7, 8]
- data3[2:5] → [3, 4, 5]
- data3[-4:-2] → [5, 6]
▶️要素の値を変更
リストの要素を変更するには、「リスト名[インデックス]」で変更したい要素を左辺に指定し、右辺に変更したい値を設定し代入します。
<例>
- data1 = [1, 2, 3 ,4 ,5]
- data1[1] = 10 → data1 の内容: [1, 10, 3 ,4 ,5]
変更したい要素をスライスで左辺に指定し、右辺に変更したいリストを設定し代入します。
<例>
- data1 = [1, 2, 3 ,4 ,5, 6, 7]
- data1[1:3] = [80, 90] → data1 の内容: [1, 80, 90 ,4 ,5, 6, 7] :1番目と2番目の要素を置き換え
スライスで指定した個数と、代入したいリストの大きさが違った場合、元のリストが拡張されます。
<例>
- data1 = [1, 2, 3 ,4 ,5, 6, 7]
- data1[3:5] = [‘A’, ‘B’, ‘C’, ‘D’] → data1 の内容: [1, 2, 3 , ‘A’, ‘B’, ‘C’, ‘D’, 6, 7] :3番目と4番目の要素を4個の要素で置き換え
▶️リストに要素を追加
リストの末尾に要素を追加する場合は、「リスト名.append()」を使います。
<例>
- data1 = [1, 2, 3 ,4 ,5]
- data1.append (6) → data1 の内容: [1, 2, 3 ,4 ,5, 6]
要素にリストを指定すると、リストが追加されます。
<例>
- data1 = [1, 2, 3 ,4 ,5]
- data1.append([6, 7]) → data1 の内容: [1, 2, 3 ,4 ,5, [6, 7]]
リストの任意の位置に要素を追加する場合は、「リスト名.insert (位置, 値)」を使います。
<例>
- data1 = [1, 2, 3 ,4 ,5]
- data1.insert (2, 100) → data1 の内容: [1, 2, 100, 3 ,4 ,5]
▶️リストの要素を削除
リストの要素を削除するには、「del リスト名[インデックス]」で指定した要素を削除します。
<例>
- data1 = [1, 2, 3 ,4 ,5]
- del data1[2] → data1 の内容: [1, 2, 4 ,5]
「リスト名.remove (値)」を使うと、指定した値に一致する要素をリストから削除します。
<例>
- data1 = [1, 2, 3 ,4 ,5, a, 6, a]
- data1.remove (a) → data1 の内容: [1, 2, 3, 4 ,5, 6]
▶️リストの長さを取得
リストの長さを取得する場合は、「len (リスト名)」を使います。
<例>
- data1 = [1, 2, 3 ,4 ,5, 6]
- len (data1) → 6
▶️リストの連結
リストを連結して新しいリストを作成する場合は、「+」演算子を使います。
<例>
- data1 = [1, 2, 3]
- data2 = [4 ,5, 6]
- data3 = data1 + data3 → data3 の内容: [1, 2, 3, 4 ,5, 6]
既存のリストの末尾に別のリストを連結する場合は、「リスト名.extend (別のリスト)」を使います。
<例>
- data1 = [1, 2, 3]
- data1.extend ([4 ,5, 6]) → data1 の内容: [1, 2, 3, 4 ,5, 6]
関数
関数は命令を集め決まった処理を行う機能です。
関数を呼び出した処理から引数(パラメータ)を受け取り、処理を行った後、結果を戻り値として呼び出し元に返します。
但し、関数によっては、引数を受取らないもの、戻り値を返さないもの、その両方があります。
関数の定義
関数は、次のように※インデントされたブロック内にまとめて定義されます。
def 関数名 (引数1, 引数2, ・・・) :
文
・・・
return 戻り値
| 項 目 | 説 明 |
| def 関数名 (引数1, 引数2, ・・・) : | 「def」文はコロン「:」で終了します。 |
| 関数名 | 変数名と同様に「識別子」と言われる一定の規則にしたがって設定します。 |
| 引数 | 関数の中で使われる変数で、呼び出し元から渡される値を「実引数」、受け取り側の変数を「仮引数」と言います。 |
| 文 | プログラムの実行(処理)の単位です。 |
| ブロック | 一つのまとまりとして実行される、命令のかたまりで、※インデントされた文の集まりです。 |
| return 戻り値 | 関数で処理した結果を戻り値として、return命令を使って呼び出し元に返します。 return命令が処理されたところで関数が終了し呼び出し元に処理が戻りますので、ブロック内の記述する場所には注意が必要です。 |
※インデント
MicroPythonはインデント(字下げ)は文の見やすさではなく、「ブロック(命令のかたまり)」を表わしますので、むやみにインデントをしてはいけません。
「ラズパイPicoWで実験」では、半角空白(スペース)4個分で表します。
関数の呼出し
関数は、次の形式で呼び出されます。
呼びされた関数はブロック内部で処理を行い、処理を終了した後、呼び出し元に処理を戻します。
関数名 (引数1, 引数2, ・・・)
| 引 数 | 説 明 |
| 位置引数 | 関数を定義した時の「仮引数の順番」と、関数を呼び出した時に渡す実引数の順番が一致する形式の引数です。 <例> def samp(a, b, c,) : ・・・ samp(1, 2, 3) |
| キーワード引数 | 関数を定義した時の仮引数の名前指定して、実引数を渡す形式の引数です。 <例> def samp(a, b, c,) : ・・・ samp(c=3, a=1, b=2) |
関数の定義は、その関数を呼び出す前に記述する必要があります。
スコープについて
スコープとは、変数が参照される範囲のことで、全てのコードから参照できる「グローバルスコープ」と、定義された関数の中だけで参照できる「ローカルスコープ」があります。
グローバルスコープを持つ変数を「グローバル変数」と言い関数の外側で宣言され、ローカルスコープを持つ変数を「ローカル変数」と言い、関数の内側で宣言されます。
関数の中で宣言された変数であっても、「global」文を使うことで、グローバル変数として扱うことができます。
| 例 | 説 明 |
| x= 1 | 変数xは関数の外側で宣言されているため、グローバル変数となり、関数samp1( )~samp5( )から参照することができます。 |
| def samp1( ) : y = 2 ・・・ | 変数yは関数samp1( )内で宣言されているローカル変数であるため、他の関数から参照することはできません。 |
| def samp2( ) : z = 1 ・・・ | 変数zは関数samp2( )内で宣言されているローカル変数であるため、他の関数から参照することはできません。 |
| def samp3( ) : global a ・・・ | 変数aはglobal文で指定されていますので、グローバル変数となり、全ての関数から参照することができます。 |
| def samp4( ) : x = 99 ・・・ | グローバル変数xを更新しようとしても、samp4( )内で宣言した変数xはローカル変数として認識されますので、更新できません。同じ名前でも別の変数です。 |
| def samp5( ) : global x x = 99 ・・・ | 変数xをglobal文で指定すると、グローバル変数となりますので、更新できます。 |
グローバル変数はプログラム全体でアクセス可能であるため、適切に使用しないと混乱を招く恐れがあります。
グローバル変数は必要最低限に抑え、なるべくローカル変数を使うことが望ましいです。
クラス
MicroPythonはあらかじめ組み込まれている、数値や文字列、論理値、リストなどのデータ型の他に、ユーザが独自のデータ型を作成することができます。
データ型は「クラス」とも呼ばれ、クラスそのものは、定義した機能を実現するための設計図(ひな形)であり、実際にプログラムで使う場合は、メモリ上に実体を生成(インスタンス化)する必要があります。
クラスをインスタンス化した実体のことを、インスタンスまたはオブジェクトと言います。
クラスの基本的な定義
クラスはデータと処理をまとめた構成になっており、基本的には次のような構造になっています。
class クラス名 :
クラス本体
| 項 目 | 説 明 |
| class クラス名 : | 「class」文はコロン「:」で終了します。 |
| クラス名 | 変数名と同様に「識別子」と言われる一定の規則にしたがって設定します。 |
| クラス本体 | 変数、※メソッド等で構成されます。 |
※メソッド
メソッドは関数と同様ですが、クラスに属さない通常の関数と区別するために、クラスに属する関数をメソッドと呼びます。
以下、果物クラス(Fruit)を定義して解説していきます。
クラスの使い方(インスタンスの生成)
インスタンスを表わす変数(インスタンス名)に、「クラス名()」を代入することで、定義したクラスを使うことができます。
インスタンス名 = クラス名( )
| 例 | 説 明 |
| class Fruit() : pass | Fruit()クラスを定義します。 何も行わないクラス(空のブロック)として指定する場合は「pss」命令を使います。 |
| app = Fruit() | Fruit()型の中身が空のインスタンス(app)を生成します。 |
独自のデータ型を含め、MicroPythonで扱うすべてのデータ型(クラス)はオブジェクトです。
オブジェクトは、数値や文字列などを保存するために割り当てられたメモリの領域と考えることができます。
オブジェクトは変数名などの名前で参照され、オブジェクトが保存されているメモリのアドレス を表わす「オブジェクトID(固有値)」で管理されています。
独自のデータ型(クラス)である「Fruit」はインスタンス名(変数)「app」に代入することで、プログラムで使うことができます。
これと、同様に文字列の場合は、正確には「data = str(”本日は晴天なり")」のように、str関数を使ってstr型にインスタンス化します。
しかし、文字列や数値のように、よく使うデータ型については作業の簡略化のため、リテラル表現を使います。
str関数等は型を変換する場合に使い、インスタンス化のために使うことはしません。
初期化メソッドの追加とインスタンスの生成
初期化メソッドはコンストラクタとも呼ばれ、インスタンス生成の際、最初に自動的に処理されるメソッドです。
▶️初期化メソッド
class クラス名 :
初期化メソッド :
self.インスタンス変数
| 項 目 | 説 明 |
| 初期化メソッド : | 「__init__」(アンダーバー2個initアンダーバー2個)で表された、「コンストラクタ」と呼ばれる特別なメソッドです。 第一引数に「※self」を記述します。 |
| インスタンス変数 | インスタンスに属する変数で、通常は変数の先頭に「self.」を付けます。 |
※self引数
selfは生成しようとするインスタンスそのものを表わしています。
| 例 | 説 明 |
| class Fruit() : | Fruit()クラスを定義します。 |
| def __init__(self, name, unit_price) : self.nm = name self.ut_pric = unit_price | 初期化メソッドを定義し、引数としてnameと unit_priceを受け取ります。 インスタンス変数として、nm、ut_pricを設定し、それぞれ受け取った引数を代入します。 |
クラスブロック、関数ブロックごとにインデントを設定する必要がありますので、注意が必要です。
▶️インスタンスの生成
初期化メソッドを追加したクラスのインスタンスに生成は、「クラスの使い方(インスタンスの生成)」と同様です。
| 例 | 説 明 |
| app = Fruit("Apple", 120,) | Fruit()型のインスタンス(app)を生成します。 実引数として"Apple"、120を設定します。 |
インスタンス変数の参照
インスタンス変数の参照は、一般的に生成したインスタンスのインスタンス変数を変数に代入します。
変数 = インスタンス名.(ドット演算子)インスタンス変数名
上記で生成したappインスタンスのインスタンス変数を参照します。
| 参 照 | 結 果 |
| dt_name = app.nm | dt_name → Apple |
| dt_unit_price = app.ut_pric | dt_unit_price → 120 |
メソッドの追加
メソッドは初期化メソッドのメソッド名「__init__」と「return命令」の使用を除き、同様な構造となっています。(初期化メソッドはメソッドの特別なケースです。)
インデントされたブロック内にまとめて定義されますが、第一引数には初期化メソッドと同様に「self」を設定します。
- インスタンス変数はインスタンスに属する変数で、通常は変数の先頭に「self.」を付けます。
- 関数と同様に、処理した結果を戻り値として、return命令を使って呼び出し元に返します。
- return命令が処理されたところで関数が終了し、呼び出し元に処理が戻りますので、ブロック内の記述する場所には注意が必要です。
def メソッド名 (self, 引数1, 引数2, ・・・) :
self.インスタンス変数
・・・
return 戻り値
| 例 | 説 明 |
| class Fruit() : | Fruit()クラスを定義します。 |
| def __init__(self, name, unit_price) : self.nm = name self.ut_pric = unit_price | 初期化メソッドを定義し、引数としてnameと unit_priceを受け取ります。 インスタンス変数として、nm、ut_pricを設定し、それぞれ受け取った引数を代入します。 |
| def get_name(self) : return self.nm | name(果物名)を返すメソッドです。 |
| def get_unit_price(self) : return self.ut_pric | unit_price(単価)を返すメソッドです。 |
| def get_total_price(self, quantity) : return self.ut_pric * quantity | quantity(数量)を受け取り、果物の合計(単価x数量)を返すメソッドです。 |
メソッドの使用
一般的に生成したインスタンスのメソッドを呼びして、結果を変数に代入します。
変数 = インスタンス名.(ドット演算子)メソッド名
| 例 | 説 明・結果 |
| app = Fruit("Apple", 120,) | Fruit()型のインスタンス(app)を生成します。 実引数として"Apple"、120を設定します。 |
| dt_name = app. get_name() | 名前:dt_name → Apple |
| dt_unit_price = app.get_unit_price() | 単価:dt_unit_price → 120 |
| dt_total_price = app.get_total_price(2) | 合計:dt_total_price → 2 X 120 = 240 |
果物クラスのコード
解説してきたコードは次のとおりです。結果表示はprint()で行っています。
#果物クラス(Fruit)を定義
class Fruit() :
#初期化メソッド(コンストラクタ)
def __init__(self, name, unit_price) :
#果物名を設定
self.nm = name
#果物の単価を設定
self.ut_pric = unit_price
#果物の名前を取得
def get_name(self) :
return self.nm
#果物の単価を取得
def get_unit_price(self) :
return self.ut_pric
#果物の数量を受け取り、単価を掛けてく合計を計算して取得
def get_total_price(self, quantity) :
return self.ut_pric * quantity
#Fruit()型のインスタンス(app)を生成。実引数として"Apple"、120を設定。
app = Fruit("Apple", 120,)
#名前を取得(Apple)
dt_name = app.get_name()
#単価を取得(120)
dt_unit_price = app.get_unit_price()
#数量2個の合計を取得(2 X 120 = 240)
dt_total_price = app.get_total_price(2)
#結果の表示
print("果実名:", dt_name)
print("単価:", dt_unit_price, "円")
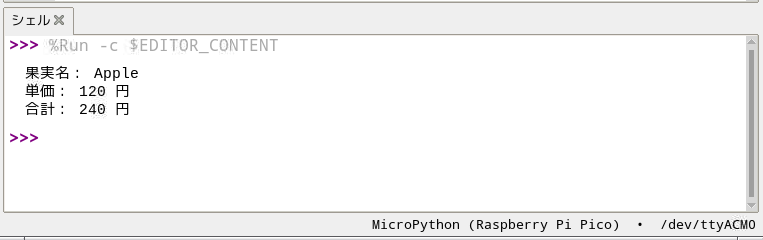
print("合計:", dt_total_price, "円")Thonnyを起動して、エディタに上にコードを入力またはコピー/貼り付けして実行すると、シェルに次の結果が表示されます。